Gracias por enviar su consulta! Uno de los miembros de nuestro equipo se pondrá en contacto con usted en breve.
Gracias por enviar su reserva! Uno de los miembros de nuestro equipo se pondrá en contacto con usted en breve.
Temario del curso
1. Comprender la clasificación mediante el uso de los vecinos más cercanos
- El algoritmokNN
- Cálculo de la distancia
- Elegir un kapropiado
- Preparación de datos para su uso con kNN
- ¿Por qué el algoritmo kNN es perezoso?
2. Entendiendo el Bayes ingenuo
- Conceptos básicos de los métodos bayesianos
- Probabilidad
- Probabilidad conjunta
- Probabilidad condicional con teoremade Bayes
- El ingenuo algoritmode Bayes
- La ingenua clasificaciónde Bayes
- El estimador de Laplace
- Uso de características numéricas con Bayes ingenuo
3. Comprender los árboles de decisión
- Divide y vencerás
- El algoritmodel árbol de decisión C5.0
- Elegir la mejor división
- Poda del árbol de decisión
4. Comprender las reglas de clasificación
- Sepárate y conquista
- El algoritmode la regla única
- El algoritmoRIPPER
- Reglas de los árboles de decisión
5. Comprender la regresión
- Regresiónlineal simple
- Estimación demínimos cuadrados ordinarios
- Correlaciones
- Regresión lineal múltiple
6. Comprender los árboles de regresión y los árboles modelo
- Adición de regresión a los árboles
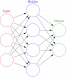
7. Comprender las redes neuronales
- De las neuronas biológicas a las artificiales
- Funcionesde activación
- Topología de red
- El número de capas
- La dirección de lainformación
- El número de nodos de cada capa
- Entrenamiento de redes neuronales con retropropagación
8. Comprensión de las máquinas de vectores de soporte
- Clasificación con hiperplanos
- Encontrar el máximo margen
- El caso de los datoslinealmente separables
- El caso de los datosno separables linealmente
- Uso de kernels para espacios no lineales
9. Comprender las reglas de asociación
- El algoritmo Apriori para el aprendizajede reglas de asociación
- Medición del interés de las reglas: apoyo y confianza
- Construyendo un conjunto de reglas con el principio Apriori
10. Descripción de la agrupación en clústeres
- Agrupación en clústeres como tarea de aprendizaje automático
- El algoritmo k-means para la agrupación en clústeres
- Uso de la distancia para asignar y actualizar clústeres
- Elección del número adecuado de clústeres
11. Medición del rendimiento para la clasificación
- Trabajar con datosde predicción de clasificación
- Una mirada más cercana a las matricesde confusión
- Uso de matrices de confusión para medir el rendimiento
- Más allá de la precisión: otras medidas de rendimiento
- La estadísticakappa
- Sensibilidad y especificidad
- Precisión y recuperación
- La medida F
- Visualización de las compensaciones derendimiento
- CurvasROC
- Estimación del rendimientofuturo
- El métodode exclusión
- Validacióncruzada
- Bootstrap muestreo
12. Ajuste de los modelos de stock para un mejor rendimiento
- Uso del símbolo de intercalación para el ajuste automatizado deparámetros
- Creación de un modeloajustado simple
- Personalización del procesode ajuste
- Mejora del rendimiento del modelo con metaaprendizaje
- Comprensión de losconjuntos
- Embolsado
- Impulsar
- Bosques aleatorios
- Entrenamiento de bosques aleatorios
- Evaluación del rendimiento aleatorio del bosque
13. Deep Learning
- Tres clases de aprendizaje profundo
- Autocodificadores profundos
- Profundo preentrenado Neural Networks
- Redes de apilamiento profundo
14. Discusión de áreas de aplicación específicas
21 Horas
Testimonios (1)
Very flexible.
Frank Ueltzhoffer
Curso - Artificial Neural Networks, Machine Learning and Deep Thinking
Traducción Automática